SymmetricDS is an open source database replication server that captures, routes, and batches data changes for synchronization between multiple databases. Configuration and runtime information is stored in a database model that provides a consistent, accessible view of operations. Let’s take a quick look at how SymmetricDS works conceptually from setup to synchronizing.
Configuring Synchronization
The configuration data model is a set of tables where the user describes the network of nodes, the data that will sync, and how data will be transferred. A node is an instance of SymmetricDS which is connected to a database. Each node has an entry in the SYM_NODE table with a unique internal node ID used by the system and an external node ID for use by the user. Since many nodes in the system will share common characteristics, each one is assigned a node group from SYM_NODE_GROUP. To connect nodes together for syncing data, they are linked with an entry in the SYM_NODE_GROUP_LINK table. The link can be specified as a “push”, where the source node sends its changes, or a “pull”, where the destination polls the source node for changes.
The data to sync starts with logical triggers that can capture insert, update, and delete operations to tables. The user specifies the source table name and its location in a catalog and schema. A wildcard character can be used to match multiple tables instead of entering each one separately. If not all columns are wanted, a list of columns can be excluded, which creates a vertical subset. Configuring a logical trigger will cause the SymmetricDS server to create physical triggers on tables in the database.
Getting data to the destination node is called routing, which is the responsibility of routers. A simple router is the default router, which sends data to all nodes. A column match router can look for specific values in a column before sending the data to a node. It can wait for the external ID of the node to appear in a column before sending it to that node. Other routers can query the database or run custom scripts to figure out where data will be sent. A router is associated to the trigger, and it provides the ability to create a horizontally subset.
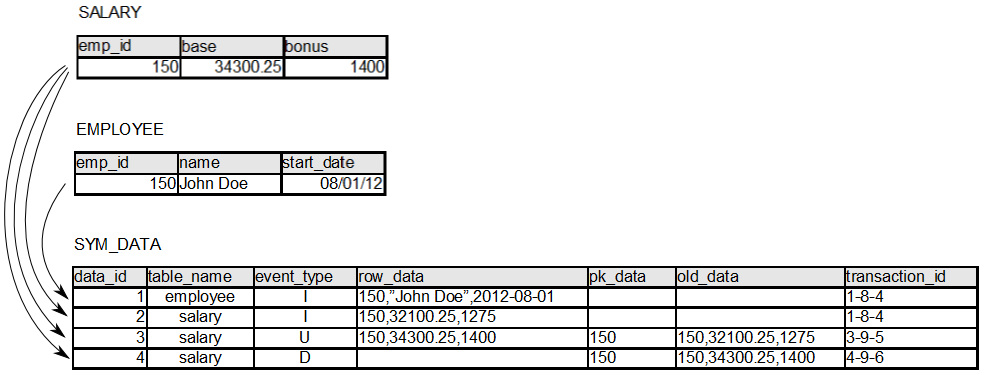
Change Data Capture
The logical trigger definitions result in database triggers being placed on tables to capture data to the SYM_DATA table. Capturing change data in this table allows SymmetricDS to guarentee ordering and atomicity of transational data, which means data is played back on the destination node exactly how it was recorded. An entry records a unique data ID sequence number, the event type (insert, update, or delete), a transaction ID, and change data. The transaction ID is shared by data committed as part of the same transaction. To accomodate different tables, change data is stored in comma separated value (CSV) format. Inserts record only the new row data. Deletes record the old row data along with the primary keys used. Updates record the new row data, old row data, and primary keys used.
{kind=link}
Routing and Batching
The routing job runs periodically in the background to group changes into batches and assign them to destination nodes for delivery. The change data is passed through the configured routers to determine which nodes will receive the data. If default routers are being used, the data is assigned to all nodes and given the same batch number. Otherwise, each node gets its own batch number for data routed to it. Data is assigned to the same batch until it reaches the max batch size. If the user configured a transactional batch algorithm, the batch can grow larger when more data includes the same transaction ID. The assignment of data to a batch is recorded in the SYM_DATA_EVENT table along with router ID that determined the assignment. The assignment of a batch to a node is recorded in the SYM_OUTGOING_BATCH table.

Syncing Data
Nodes that are linked together in the configuration will synchronize their data using either the “push” or “pull” action specified. A push is where one node connects to another and pushes its changes, while a pull is where one node waits for other nodes to connect and receive their changes. Each action is performed at a timed interval, but the push only connects over the network when there are changes to send, while the pull always connects to see if there are changes waiting. The pull is useful where the connecting node is behind a firewall that allows outgoing connections but not incoming ones.


The status of the batch is recorded both on the source side, in the SYM_OUTGOING_BATCH table, and on the destination side, in the SYM_INCOMING_BATCH table. Batch status in both databases makes it easy to find problems with data replication regardless of which system you’re using. For a network with a central node that sends and receives changes with remote nodes, it has the advantage of seeing any data replication error across the network from a central location.
Find Out More
To learn more about SymmetricDS data synchronization, the User Guide can be read online and is included in the software download. For hands on experience to quickly see data syncing in action, try the SymmetricDS Tutorial that follows an example of a retail store data sync scenario.